In order to be able to work with Moose there is a prerequisite we cannot avoid: we need a model to analyze. This can be archieved in 2 principal ways:
Importing an existing JSON/MSE file containing a model
Importing a model via a Moose importer such as the Pharo importer or Python importer
While doing this, we create a lot of entities and set a lot of relations. But this can take some time. I found out that this time was even bigger than I anticipated while profiling a JSON import.
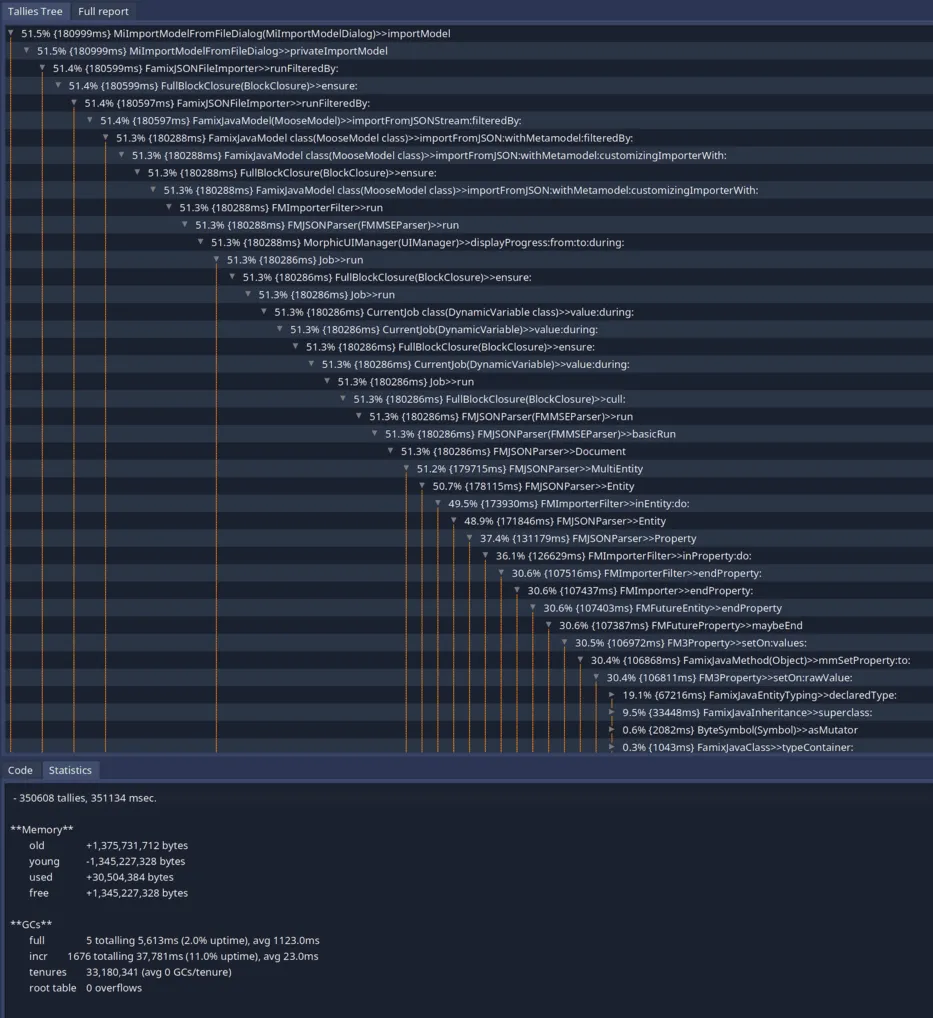
Here is the result of the profiling of a JSON of 330MB on a Macbook pro M1 from 2023:
Form this profiling we can see that we spend 351sec for this import. We can find more information in this report:
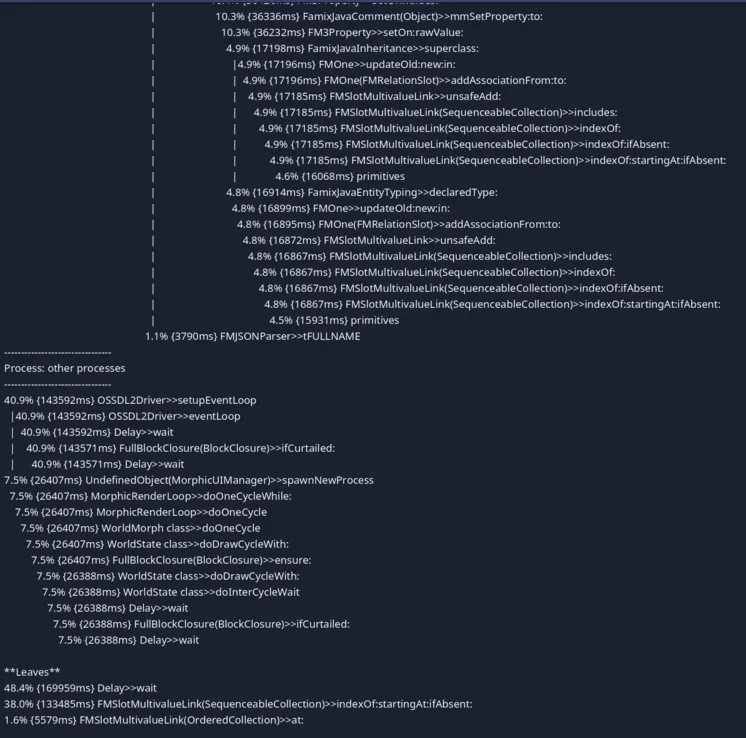
On this screenshot we can see some noise due to the fact that the profiler was not adapted to the new event listening loop of Pharo. But in the leaves we can also see that most of the time is spent in FMSlotMultivaluedLink>>#indexOf:startingAt:ifAbsent:.
This is used by a mecanism of all instance variables that are FMMany because those we do not want duplicated elements. Thus, we check if the collection contains the element before adding it.
But during the import of a JSON file, we should have no duplicates making this check useless. This also explains why we spend so much time in this method: we always are in the worst case scenario: there is no element matching.
In order to optimize the creation of a model when we know we will not create any duplicates, we can disable the check.
For this, we can use a dynamic variable declaring that we should check for duplicated elements by default, but allowing to disable the check during the execution of some code.
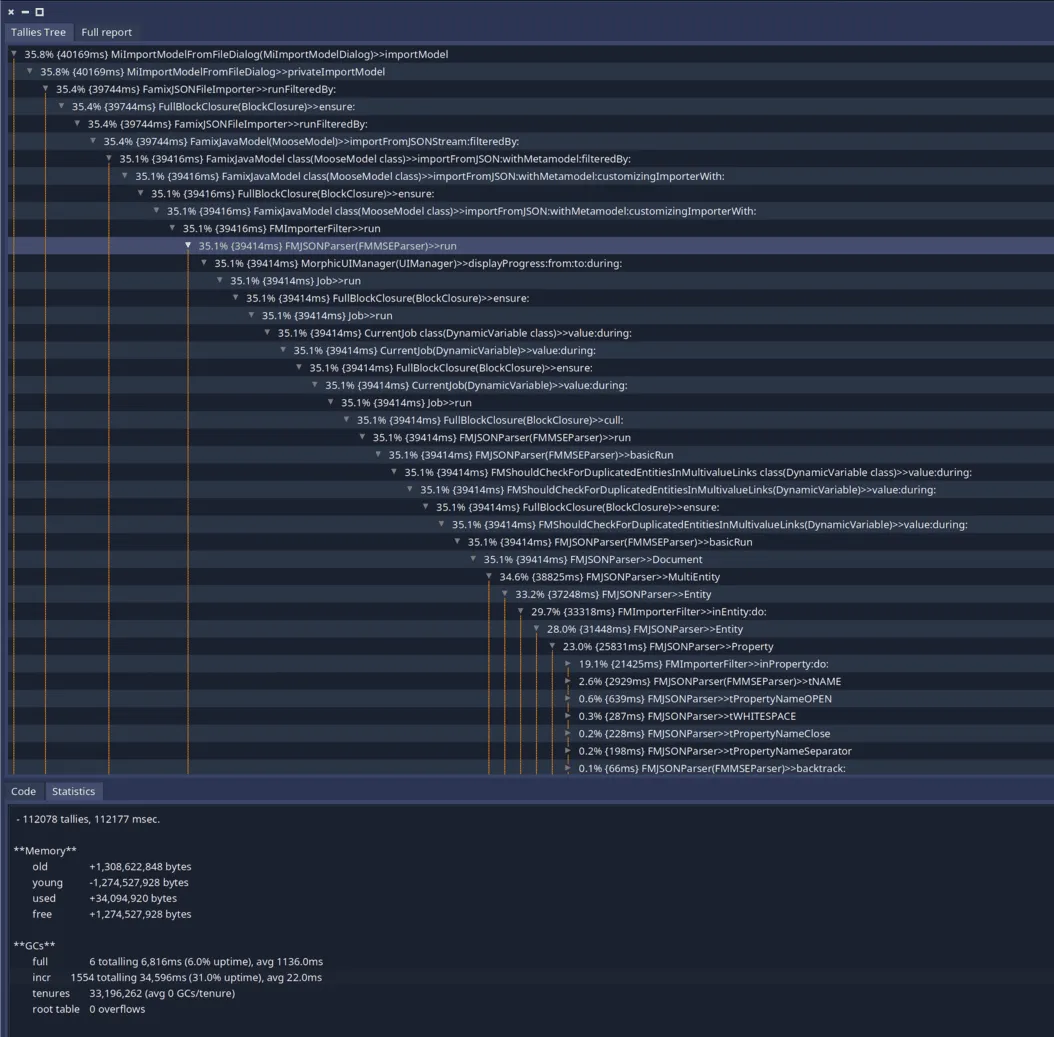
Now let’s try to import the same JSON file with the optiwization enabled:
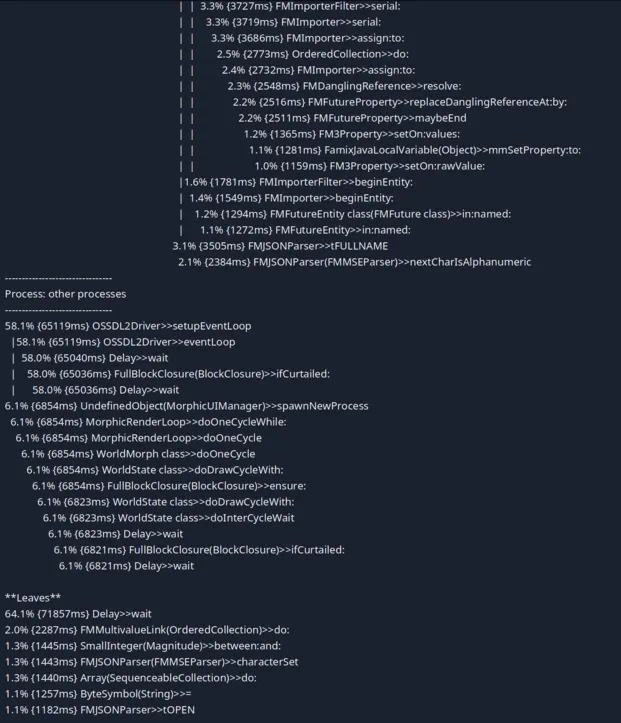
We can see that the import time went from 351sec to 113sec!
We can also notice that we do not have one bottleneck in our parsing. This means that it will be harder to optimize more this task (even if some people still have some ideas on how to do that).
This optimization has been made for the import of JSON but it can be used in other contexts.
For example, in the Moose Python importer, the implementation is sure to never produce a duplicate. Thus, we could use the same trick this way:
FamixPythonImporter >> import
FMShouldCheckForDuplicatedEntitiesInMultivalueLinks value: false during: [ super import ]
When developping algorithm on top of the Moose platform, we can easily hurt a wall during testing.
To do functional (and sometimes unit) testing, we need to work on a Moose model. Most of the time we are getting this model in two ways:
We produce a model and save the .json to recreate this model in the tests
We create a model by hand
But those 2 solutions have drawbacks:
Keeping a JSON will not follow the evolutions of Famix and the model produce will not be representative of the last version of Famix
Creating a model by hand has the drawback of taking the risk that this model will not be representative of what we could manipulate in reality. For example, we might not think about setting the stubs or the source anchors
In order to avoid those drawbacks I will describe my way of managing such testing cases in this article. In order to do this, I will explain how I set up the tests of a project to build CallGraph of Java projects.
The idea I had for testing callgraphs is to implement real java projects in a resources folder in the git of the project. Then, we can parse them when launching the tests and manipulate the produced model. This would ensure that we always have a model up to date with the latest version of Famix. If tests breaks, this means that our famix model evolved and that our project does not work anymore for this language.
Now that we have the dependency running, we can use this project. We will explain the minimal steps here but you can find the full documantation here.
The usage of GitBridge begins with the definition of our FamixCallGraphBridge:
GitBridge <<#FamixCallGraphBridge
slots: {};
package: 'Famix-CallGraph-Tests'
Now that this class exists we can access our git folder using FamixCallGraphBridge current root.
Let’s add some syntactic suggar:
FamixCallGraphBridge class>>#resources
^self root /'resources'
FamixCallGraphBridge class>>#sources
^self resources /'sources'
We can now access our java projects doing FamixCallGraphBridge current sources.
This step is almost done, but in order for our tests to work in a github action (for example), we need two little tweaks.
In our smalltalk.ston file, we need to register our project in Iceberg (because GitBridge uses Iceberg to access the root folder).
SmalltalkCISpec {
#loading : [
SCIMetacelloLoadSpec {
#baseline : 'FamixCallGraph',
#directory : 'src',
#registerInIceberg : true"<== This line"
}
]
}
Also, in our github action we need to be sure that the checkout action will get enough info for git bridge to run and not the minimal ammount (which is the default) adding a fetch-depth: option.
I am using this technic to tests multiple projects such as parsers or call graph builders. In those projects I do touch my model and the setup can take time. So I optimize this setup in order to build a model only once for all the test case using a TestResource.
In order to do this we can remove the slots we added to FamixAbstractJavaCallGraphBuilderTestCase and create a test resource that will hold them
It is possible to do the same thing for other languages than java but maybe not exactly in the same way than in this blogpost for the section “Parse and import your model”. But this article is meant to be an inspiration!
I hope this helps improve the robustness of our projects :)