Creating an importer for an alien grammar
In this blog-post, we see some tricks to create a visitor for an alien AST. This visitor can allow, for example, to generate a Famix model from an external AST.
In a previous blog-post, we saw how to create a parser from a tree-sitter grammar. This parser gives us an AST (Abstract Syntax Tree) which is a tree of nodes representing any given program that the parser can understand. But the structure is decided by the external tool and might not be what we want. For example it will not be a Famix model.
Let see some tricks to help convert this alien grammar into something that better fits our needs.
The Visitor design pattern
Section titled “The Visitor design pattern”Let’s first look at what a “Visitor” is. If you already know, you can skip this part.
When dealing with ASTs or Famix models, visitors are very convenient tools to walk through the entire tree/model and perform some actions.
The Visitor is a design pattern that allows to perform some actions on a set of interconnected objects, presumably all from a family of classes. Typically, the classes all belong to the same inheritance hierarchy. In our case, the objects will all be nodes in an AST. For Famix, the objects would be entities from a Famix meta-model.
In the Visitor pattern, all the classes have an #accept: method.
Each #accept: in each class will call a visiting method of the visitor that is specific to it.
For example the classes NodeA and NodeB will respectively define:
NodeA >> accept: aVisitor aVisitor visitNodeA: self.
NodeB >> accept: aVisitor aVisitor visitNodeB: self.Each visiting method in the visitor will with the element it receives, knowing what is its class: in #visitNodeA: the visitor knows how to deal with a NodeA instance and similarly for #visitNodeB:.
The visitor pattern is a kind of ping-pong between the visiting and #accept: methods:

Typically, all the node are interconnected in a tree or a graph.
To walk through the entire structure, it is expected that each visiting method take care of visiting the sub-objects of the current object.
For example we could say that NodeA has a property child containing another node:
NodeVisitor >> visitNodeA: aNodeA "do some stuff" aNodeA child accept: selfIt is easy to see that if child contains a NodeB, this will trigger the visiting method visitNodeB: on it.
If it’s a instance of some other class, similarly it will trigger the appropriate visiting method.
To visit the entire structure one simply calls accept: on the root of the tree/graph passing it the visitor.
Visitors are very useful with ASTs or graphs because once all the accept: methods are implemented, we can define very different visitors that will "do some stuff" (see above) on all the object in the tree/graph.
Several of the “Famix-tools” blog-posts are based on visitors.
An external AST
Section titled “An external AST”In a preceding blog-post we saw how to create an AST from a Perl program using the Tree-Sitter Perl grammar.
We will use this as an example to see how to create a visitor on this external AST. Here “external” means it was created by an external tool and we don’t have control on the structure of the AST. If we want to create a Famix-Perl model from a Tree-Sitter AST, we will need to convert the nodes in the Tree-Sitter AST into Famix entities.
We will use a simple Perl program as example:
package Person;sub new { my $class = shift; my $self = { _firstName => shift, _lastName => shift, _ssn => shift, }; # Print all the values just for clarification. print "First Name is $self->{_firstName}\n"; print "Last Name is $self->{_lastName}\n"; print "SSN is $self->{_ssn}\n"; bless $self, $class; return $self;}sub setFirstName { my ( $self, $firstName ) = @_; $self->{_firstName} = $firstName if defined($firstName); return $self->{_firstName};}sub getFirstName { return $self->{_firstName};}(Note: In Perl, “package” is used to create classes. Therefore in our example, “new”, “setFirstName”, and “getFirstName” are some kind of Perl methods.)
Following the instructions in the previous post, you should be able to get a Tree-Sitter AST like this one:
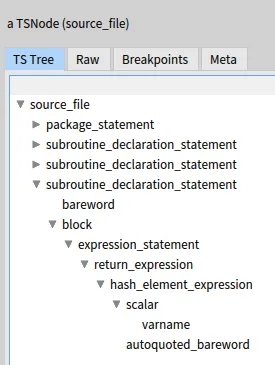
A Visitor on a Tree-Sitter AST
Section titled “A Visitor on a Tree-Sitter AST”To have a visitor for this AST, we first need to have an accept: method in all the classes of the AST’s nodes.
Fortunately this is all taken care of by the Pharo Tree-Sitter project.
In TSNode one finds:
accept: aTSVisitor ^ aTSVisitor visitNode: selfAnd a class TSVisitor defines:
visitNode: aTSNode aTSNode collectNamedChild do: [ :child | child accept: self ]Which is a method ensuring that all children of a TSNode will be visited.
Thanks guys!
But less fortunately, there are very few different nodes in a Tree-Sitter AST.
Actually, all the nodes are instances of TSNode.
So the “subroutine_declaration_statement”, “block”, “expression_statement”, “return_expression”,… of our example are all of the same class, which is not very useful for a visitor.
This happens quite often. For example a parser dumping an AST in XML format will contain mostly XMLElements. If it is in JSON, they are all “objects” without any native class specification in the format. 😒
Fortunately, people building ASTs usually put inside a property with an indication of the type of each node.
For Tree-Sitter, this is the “type” property.
Every TSnode has a type which is what is displayed in the screenshot above.
How can we use this to help visiting the AST in a meaningfull way (from a visitor point a view)?
We have no control on the accept: method in TSNode, it will always call visitNode:.
But we can add an extra indirection to call different visiting methods according to the type of the node.
So, our visitor will inherit from TSVisitor but it will override the visitNode: method.
The new method will take the type of the node, build a visiting method name from it, and call the method on the node.
Let’s decide that all our visiting methods will be called “visitPerl<some-type>”.
For example for a “block”, the method will be visitPerlBlock:, for a “return_expression” it will be `visitPerlReturn_expression:”.
This is very easily done in Pharo with this method:
visitNode: aTSNode | selector | selector := 'visitPerl' , aTSNode type capitalized , ':'. ^self perform: selector asSymbol with: aTSNodeThis method builds the new method name in a temporary variable selector and then calls it using perform:with:.
Note that the type name is capitalized to match the Pharo convention for method names.
We could have removed all the underscores (_) but it would have required a little bit of extra work.
This is not difficult with string manipulation methods.
You could try it… (or you can continue reading and find the solution further down.)
With this simple extra indirection in #visitNode:, we can now define separate visiting method for each type of TSNode.
For example to convert the AST to a Famix model, visitPerlPackage: would create a FamixPerlClass, and visitPerlSubroutine_declaration_statement: will create a FamixPerlMethod.
(Of course it is a bit more complex than that, but you got the idea, right?)
Creating the visiting methods
Section titled “Creating the visiting methods”Our visitor is progressing but not done yet.
If we call astRootNode accept: TreeSitterPerlVisitor new with the root node of the Tree-Sitter AST, it will immediately halt on a DoesNotUnderstand error because the method visitPerlSource_file: does not exist in the visitor.
We can create it that way:
visitPerlSource_file: aTSNode ^self visitPerlAbstractNode: aTSNode.
visitPerlAbstractNode: aTSNode ^super visitNode: aTSNodeHere we introduce a visitPerlAbstractNode: that is meant to be called by all visiting methods.
From the point of view of the visitor, we are kind of creating a virtual inheritance hierarchy where each specific TSNode will “inherit” from that “PerlAbstractNode”.
This will be useful in the future when we create sub-classes of our visitor.
By calling super visitNode:, in visitPerlAbstractNode: we ensure that the children of the “source_file” will be visited.
And… we instantly get a new halt with DoesNotUnderstand: visitPerlPackage_statement:.
Again we define it:
visitPerlPackage_statement: aTSNode ^self visitPerlAbstractNode: aTSNodeThis is rapidly becoming repetitive and tedious. There are a lot of methods to define (25 for our example) and they are all the same.
Let’s improve that.
We will use the Pharo DoesNotUnderstand mechanism to automate everything.
When a message is sent that an object that does not understand it, then the message doesNotUnderstand: is sent to this object with the original message (not understood) as parameter.
The default behavior is to raise an exception, but we can change that.
We will change doesNotUnderstand: so that it creates the required message automatically for us.
This is easy all we need to do is create a string:
visitPerl<some-name>: aTSNode ^self visitPerlAbstractNode: aTSNodeWe will then ask Pharo to compile this method in the Visitor class and to execute it. et voila!
Building the string is simple because the selector is the one that was not understood originally by the visitor.
We can get it from the argument of doesNotUnderstand:.
So we define the method like that:
doesNotUnderstand: aMessage | code | code := aMessage selector , ' aTSNode ^super visitNode: aTSNode'.
self class compile: code classified: #visiting.
self perform: aMessage selector with: aMessage arguments firstFirst we generate the source code of the method in the code variable.
Then we compile it in the visitor’s class.
Last we call the new method that was just created.
Here to call it, we use perform:with: again, knowing that our method has only one argument (so only one “with:” in the call).
For more security, it can be useful to add the following guard statement at the beginning of our doesNotUnderstand: method:
(aMessage selector beginsWith: 'visitPerl') ifFalse: [ super doesNotUnderstand: aMessage ].This ensures that we only create methods that begins with “visitPerl”, if for any reason, some other message is not understood, it will raise an exception as usual.
Now visiting the AST from our example creates all the visiting methods automatically:
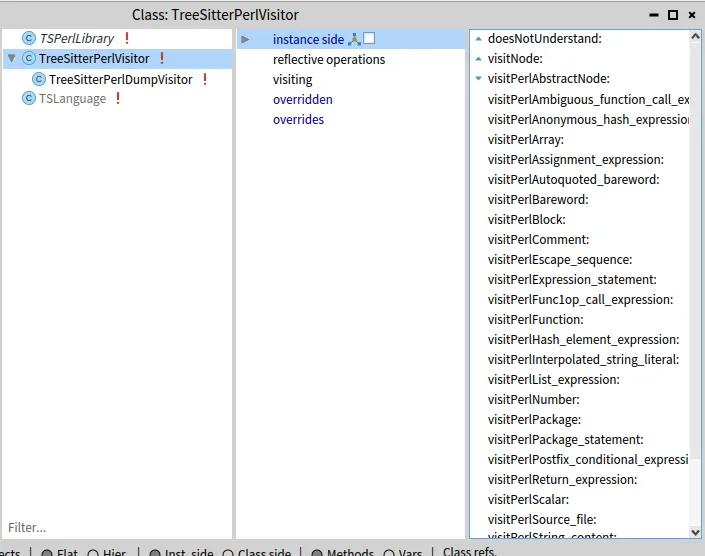
Of course this visitor does not do anything but walking through the entire AST. Let’s say it is already a good start and we can create specific visitors from it.
For example we see in the screen shot above that there is a TreeSitterPerlDumpVisitor.
It just dumps on the Transcript the list of node visited.
For this, it only needs to define:
visitPerlAbstractNode: aTSNode ('visiting a ', aTSNode type) traceCr. super visitPerlAbstractNode: aTSNode.Et voila! (number 2)
Note: Redefining
doesNotUnderstand:is a nice trick to quickly create all the visiting methods, but it is recommended that you remove it once the visitor is stable, to make sure you catch all unexpected errors in the future.
Better visiting methods
Section titled “Better visiting methods”This is all well and good, but the visiting methods have one drawback: They visit the children of a node in an unspecified order. For example, an “assignment_expression” has two children, the variable assigned and the expression assigned to it. We must rely on Tree-Sitter to visit them in the right order so that the first child is always the variable assigned and the second child is always the right-hand-side expression.
It would be better to have a name for these children so as to make sure that we know what we are visiting at any time.
In this case, Tree-Sitter helps us with the collectFieldNameOfNamedChild method of TSNode.
This method returns an OrderedDictionary where the children are associated to a (usually) meaningful key.
In the case of “assignment_expression” the dictionary has two keys: “left” and “right” each associated to the correct child.
It would be better to call them instead of blindly visit all the children.
So we will change our visitor for this.
The visitNode: method will now call the visiting method with the dictionnary of keys/children as second parameter, the dictionnary of fields.
This departs a bit from the traditional visitor pattern where the visiting methods usually have only one argument, the node being visited.
But the extra information will help make the visiting methods simpler:
visitNode: aTSNode | selector | selector := String streamContents: [ :st | st << 'visitPerl'. ($_ split: aTSNode type) do: [ :word | st << word capitalized ]. st << ':withFields:' ].
^self perform: selector asSymbol with: aTSNode with: aTSNode collectFieldNameOfNamedChildIt looks significantly more complex, but we also removed the underscores (_) in the visiting method selector (first part of the #visitNode: method).
So for “assignment_expression”, the visiting method will now be: visitPerleAssignmentExpression:withFields:.
From this, we could have the following template for our visiting methods:
visitPerlAssignmentExpression: aTSNode withFields: fields ^{ self visitKey: 'left' inDictionnary: fields. self visitKey: 'right' inDictionnary: fields. }Where visitKey: inDictionnary: takes care of the fact that several nodes may be associated to the same key.
Here it is:
visitKey: aKey inDictionnary: childrenDictionnary | child | child := childrenDictionnary at: aKey ifAbsent: [^nil].
^child isCollection ifTrue: [ child collect: [ :c | c accept: self ] ] ifFalse: [ child accept: self ]The doesNotUnderstand: method to generate all this is also more complex because there is more to generate.
Here it is:
doesNotUnderstand: aMessage (aMessage selector beginsWith: 'visitPerl') ifFalse: [ super doesNotUnderstand: aMessage ].
self class compile: (self createVisitMethod: aMessage) classified: #visiting.
self perform: aMessage selector with: aMessage arguments first with: aMessage arguments secondThe code generation has been extracted in a separate method for the sake of readability:
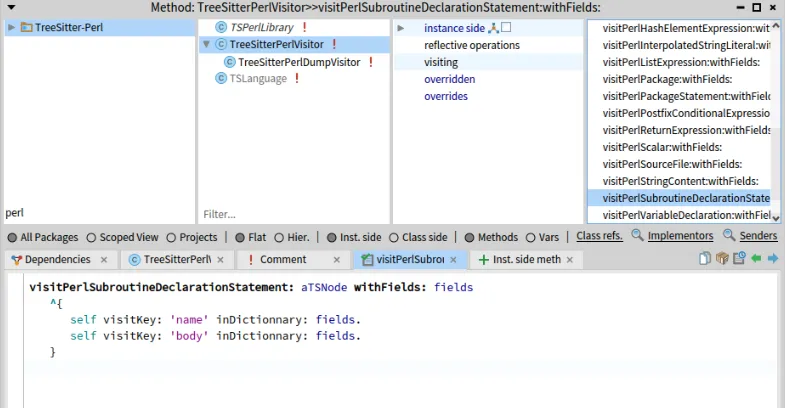
createVisitMethod: aMessage
| fields aTSNode | aTSNode := aMessage arguments first. fields := aMessage arguments second.
^String streamContents: [ :str | str << 'visitPerl'. ($_ split: aTSNode type) do: [ :word | str << word capitalized ]. str << ': aTSNode withFields: fields ^{'.
fields keysDo: [ :key | str << ' self visitKey: ''' ; << key ; << ''' inDictionnary: fields.' ; cr ]. str << ' }' ; cr ]Again, it may look a bit complex, but this is only building a string with the needed source code. Go back to the listing of #visitPerlAssignmentExpression: above to see that:
- we first build the selector of the new visiting method with its parameter;
- then we put a return and start a dynamic array;
- after that we create a call to
#visitKey:inDictionnaryfor each field; - and finally, we close the dynamic array.
Et voila! (number 3).
This is it.
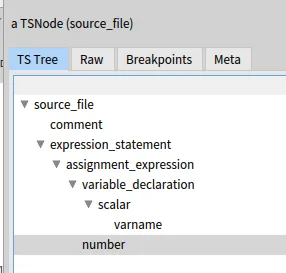
If we call again this visitor on an AST from Tree-Sitter, it will generate all the new visiting methods with explicit field visiting.
For example:
The implementation of all this can be found in the https://github.com/moosetechnology/Famix-Perl repository on github. All that’s left to do is create a sub-class of this visitor and override the visiting methods to do something useful with each node type.
That’s all for today folks.
 .
.
 {: .img-fluid}
{: .img-fluid}