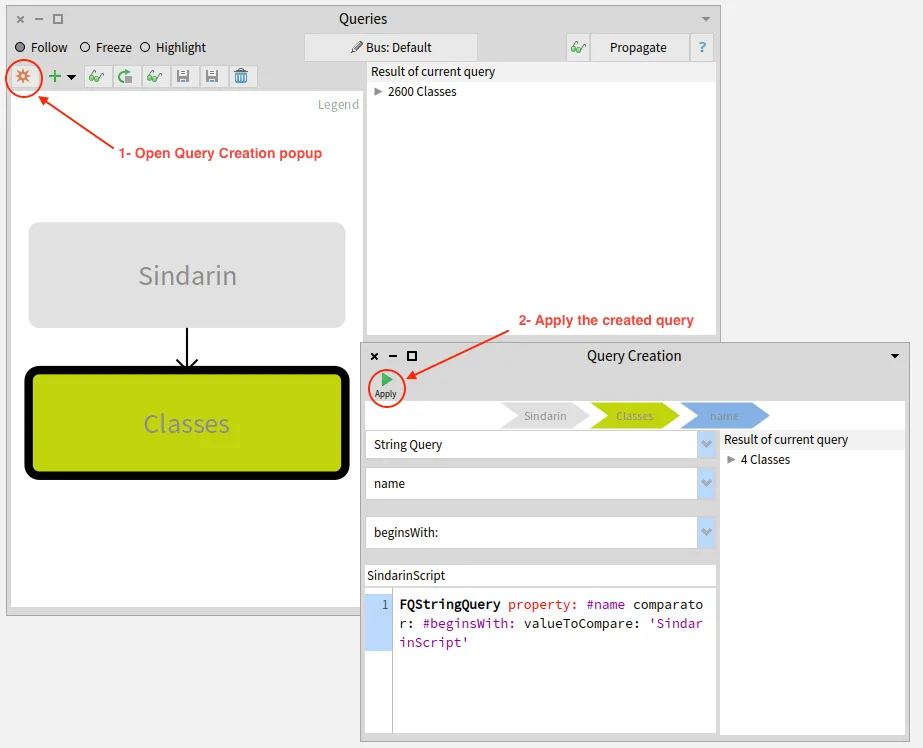
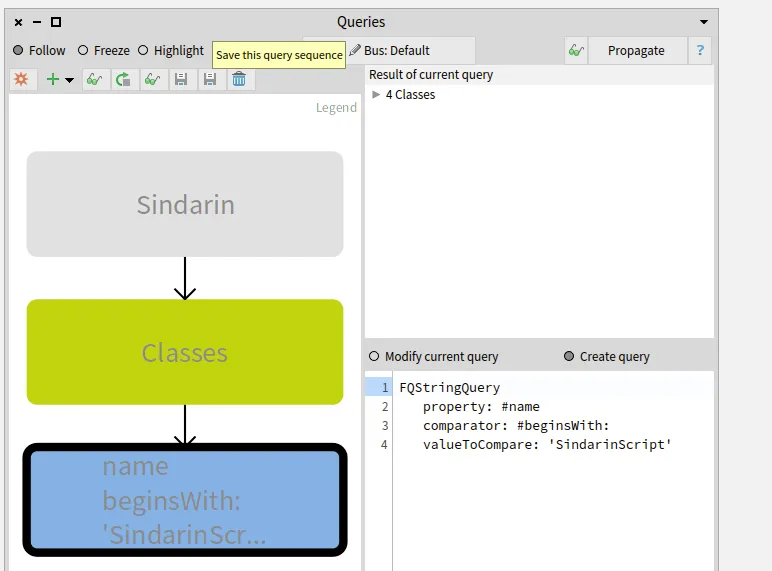
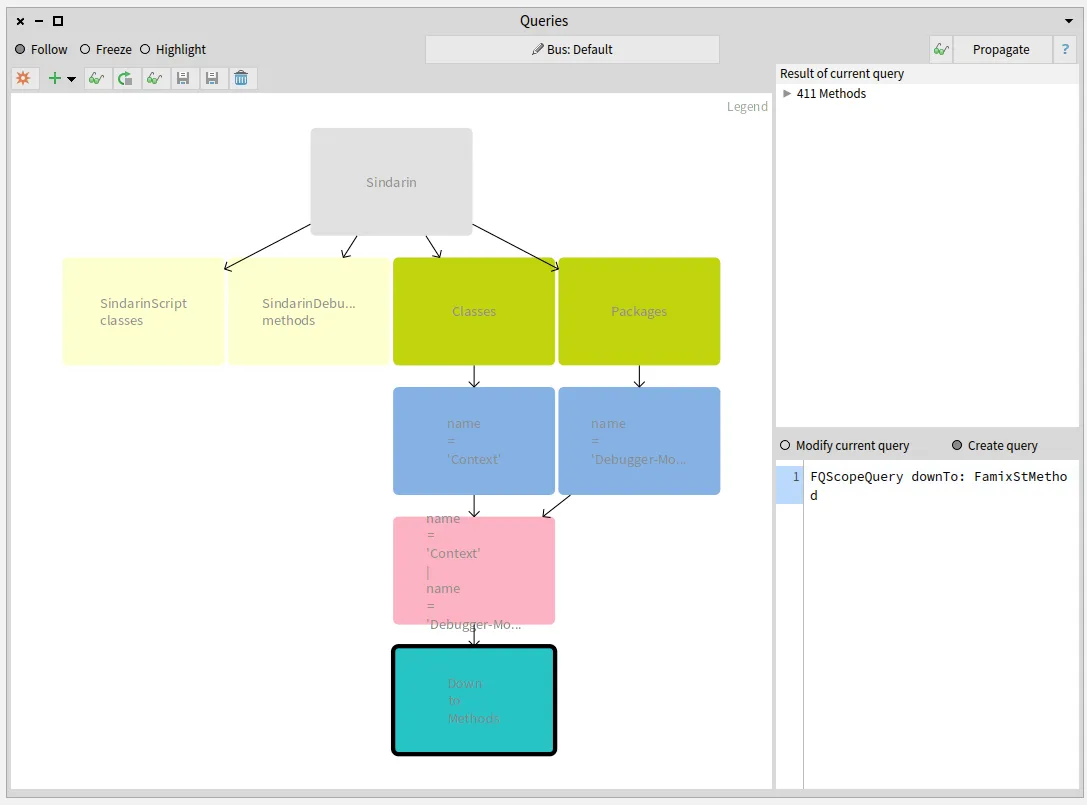
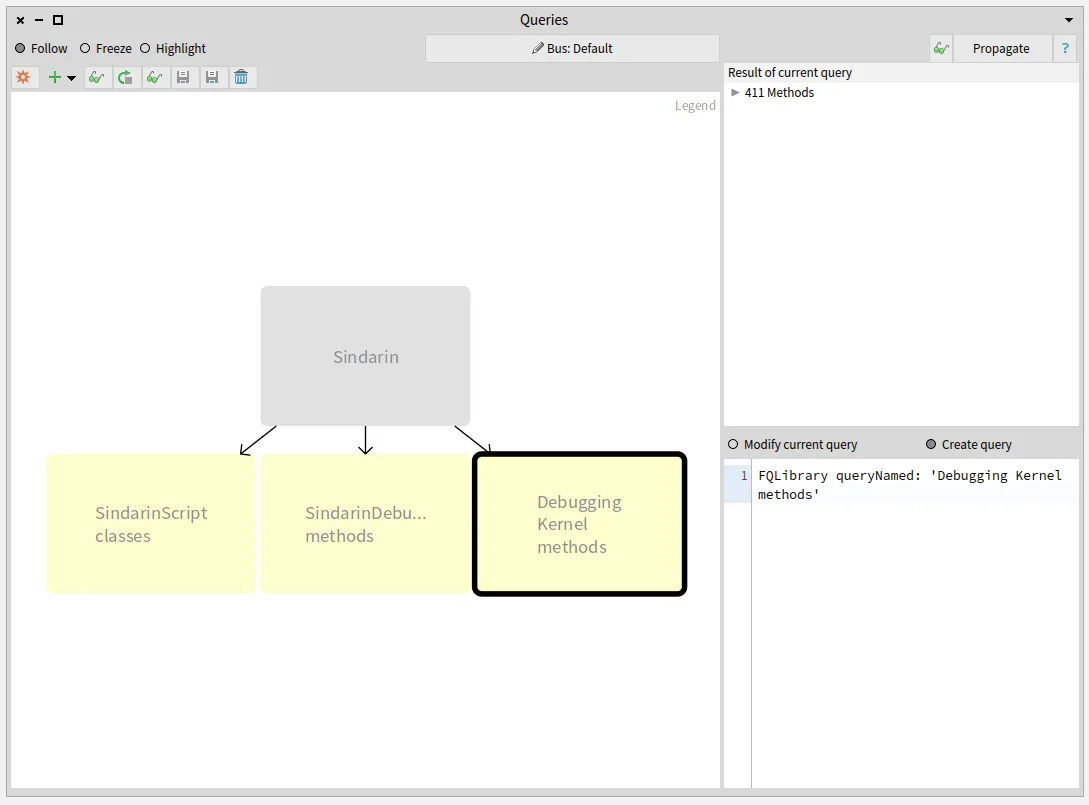
Parametrics next generation
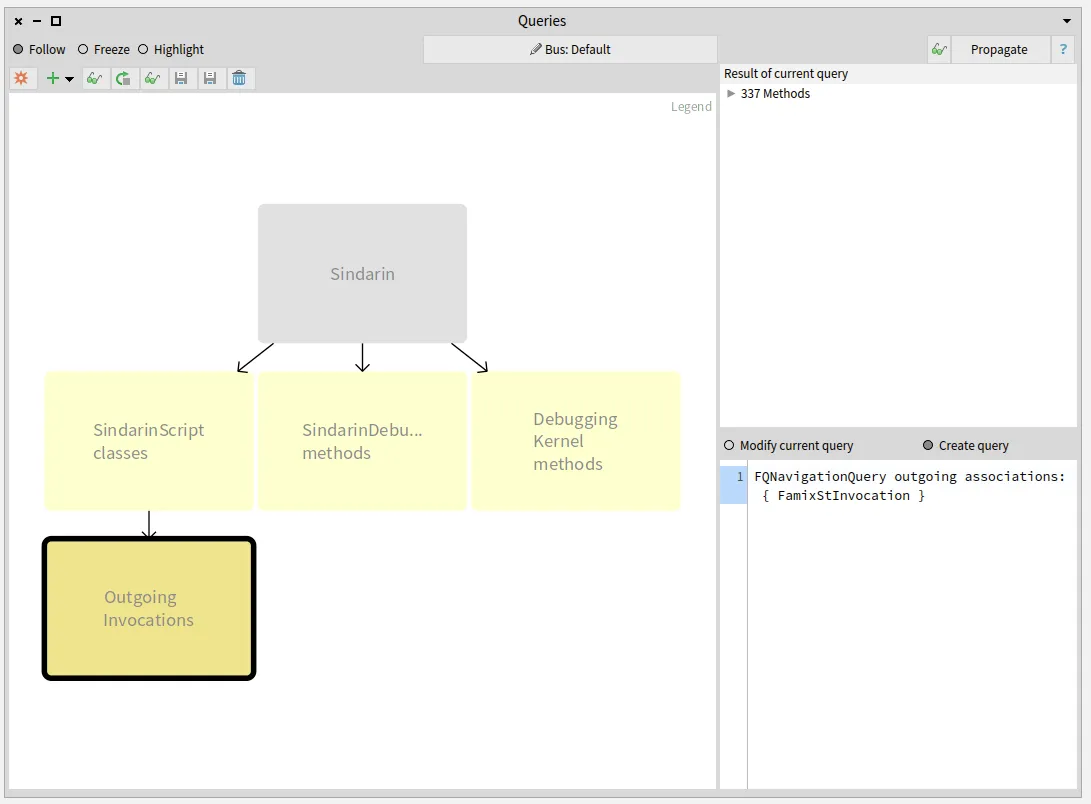
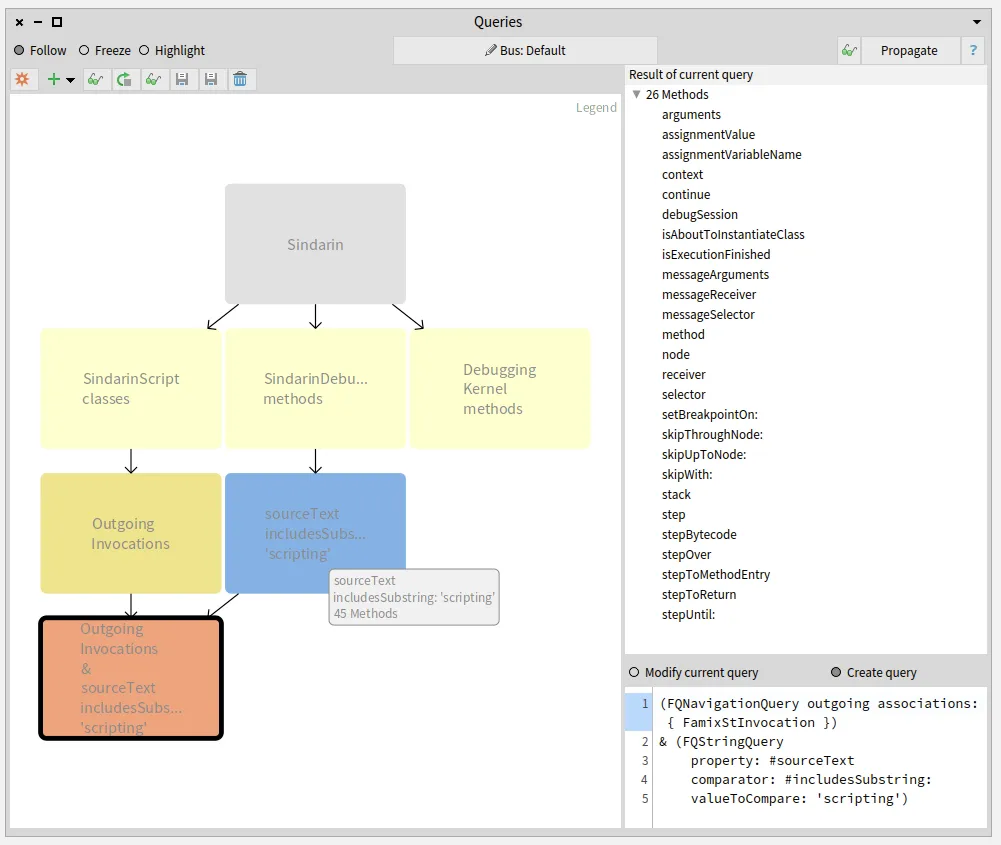
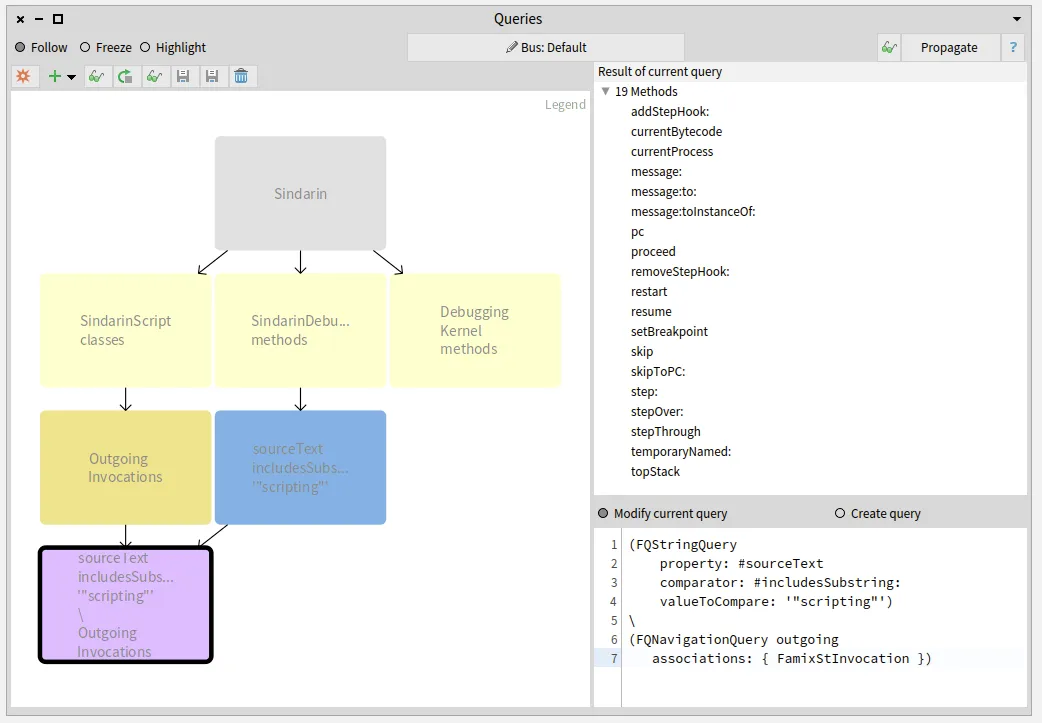
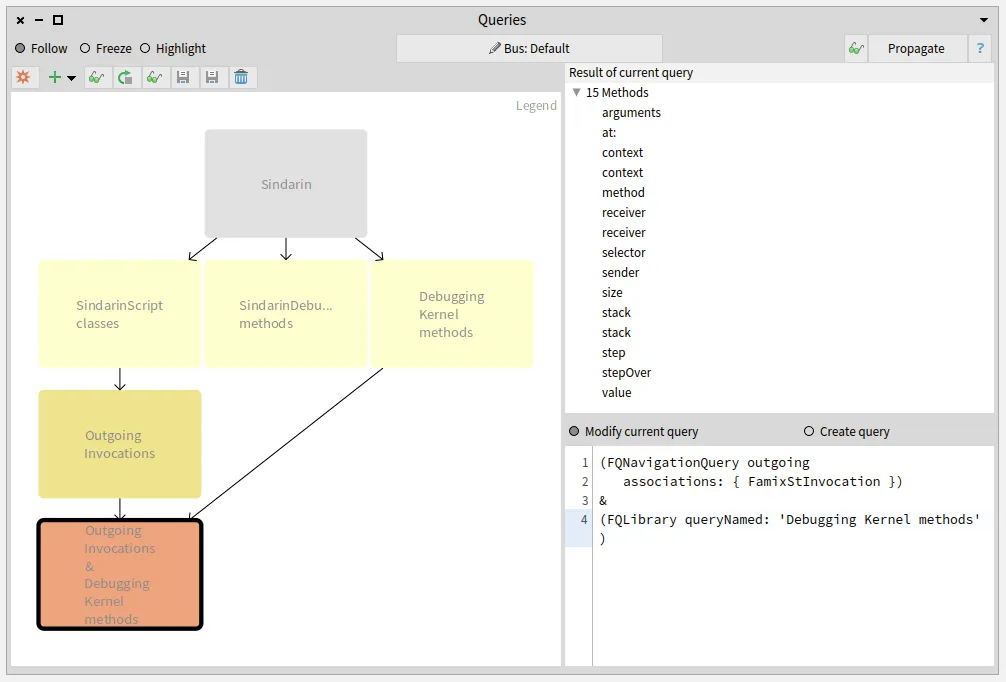
How do we represent the relation between a generic entity, its type parameters and the entities that concretize it? The Famix metamodel has evolved over the years to improve the way we represent these relations. The last increment is described in a previous blogpost. We present here a new implementation that eases the management of parametric entities in Moose.
The major change between this previous version and the new implementation presented in this post is this: We do not represent the parameterized entities anymore.
What’s wrong with the previous parametrics implementation?
Section titled “What’s wrong with the previous parametrics implementation?”Difference between parametric and non-parametric entities
Section titled “Difference between parametric and non-parametric entities”The major issue with the previous implementation was the difference between parametric and non-parametric entities in practice, particularly when trying to trace the inheritance tree. Here is a concrete example: getting the superclass of the superclass of a class.
- For a non-parametric class, the sequence is straightforward: ask the inheritance for the superclass, repeat.
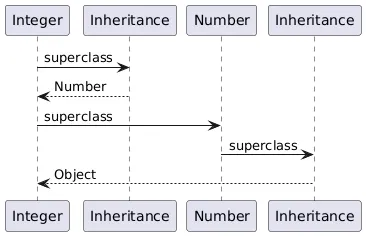
- For a parametric class (see the little code snippet below), there was an additional step, navigating through the concretization:
import java.util.ArrayList; "public class ArrayList<E> { /* ... */ }"
public MySpecializedList extends ArrayList<String> {}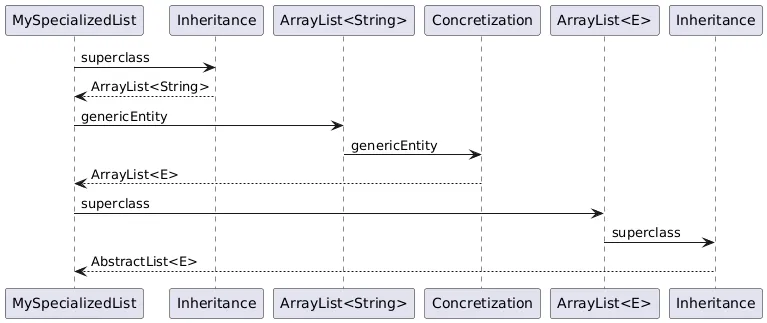
This has caused many headaches to developers who wanted to browse a hierarchy: how do we keep track of the full hierarchy when it includes parametric classes? How to manage both situations without knowing if the classes will be parametric or not? The same problem occurred to browse the implementations of parametric interfaces and the invocations of generic methods.
Naming
Section titled “Naming”The previous implementation naming choices were a little complex to grasp and did not match the standard vocabulary, especially in Java:
- A type parameter was named a
ParameterType - A type argument was named a
ConcreteParameterType
Entities duplication
Section titled “Entities duplication”Each time there was a concretization, a parametric entity was created. This created duplicates of virtually the same entity: one for the generic entity and one for each parameterized entity. Let’s see an example:
public MyClass implements List<Float> {
public List<Integer> getANumber() { List<Number> listA; List<Integer> listB; }}For the interface List<E>, we had 6 parametric interfaces:
- One was the generic one:
#isGeneric >>> true - 3 were the parameterized interfaces implemented by
ArrayList<E>, its superclassAbstractList<E>andMyClass. They were different because the concrete types were different:EfromArrayList<E>,EfromAbstractList<E>andFloat. - 2 were declared types:
List<Number>andList<Integer>.
The new implementation
Section titled “The new implementation”Parametric associations
Section titled “Parametric associations”When deciding of a new implementation, our main goal was to create a situation in which the dependencies would work in the same way for all entities, parametric or not. That’s where we introduce parametric associations. These associations only differ from standard associations by one property: they trigger a concretization.
Here is the new Famix metamodel traits that represent concretizations:
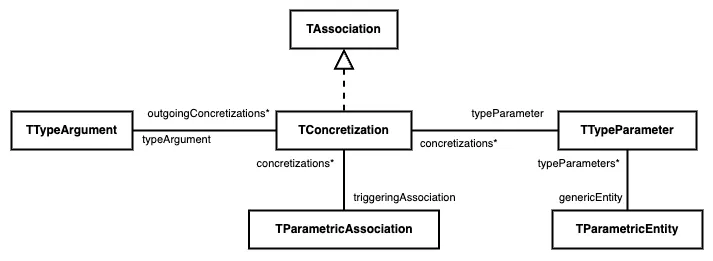
There is a direct relation between a parametric entity and its type parameters.
A concretization is the association between a type parameter and the type argument that replaces it.
A parametric association triggers one or several concretizations, according to the number of type parameters the parametric entity has. Example: a parametric association that targets Map<K,V> will trigger 2 concretizations.
The parametric entity is the target of the parametric association. It is always generic. As announced, we do not represent parameterized entities anymore.
Coming back to the entities’ duplication example above, we now represent only 1 parametric interface for List<E>and it is the target of the 5 parametric associations.
Entity typing
Section titled “Entity typing”This metamodel evolution is the occasion of another major change: the replacement of the direct relation between a typed entity and its type. This new association is called Entity typing.

The choice to replace the existing relation by a reified association is made to represent the dependency in coherence with the rest of the metamodel.
With this new association, we can now add parametric entity typings.
In a case like this:
public ArrayList<String> myAttribute;we have an “entity typing” association between myAttribute and ArrayList. This association is parametric: it triggers the concretization of E in ArrayList<E> by String.
Type parameters bounds
Section titled “Type parameters bounds”Type parameters can be bounded:
public class MyParametricClass<T extends Number> {}In the previous implementation, the bounds of type parameters were implemented as inheritances: in the example above, Number would be the superclass of T.
Since this change, bounds were introduced for wildcards.
We have now the occasion to also apply them to type parameters.
In the new implementation, Number is the upper bound of T.
Summary
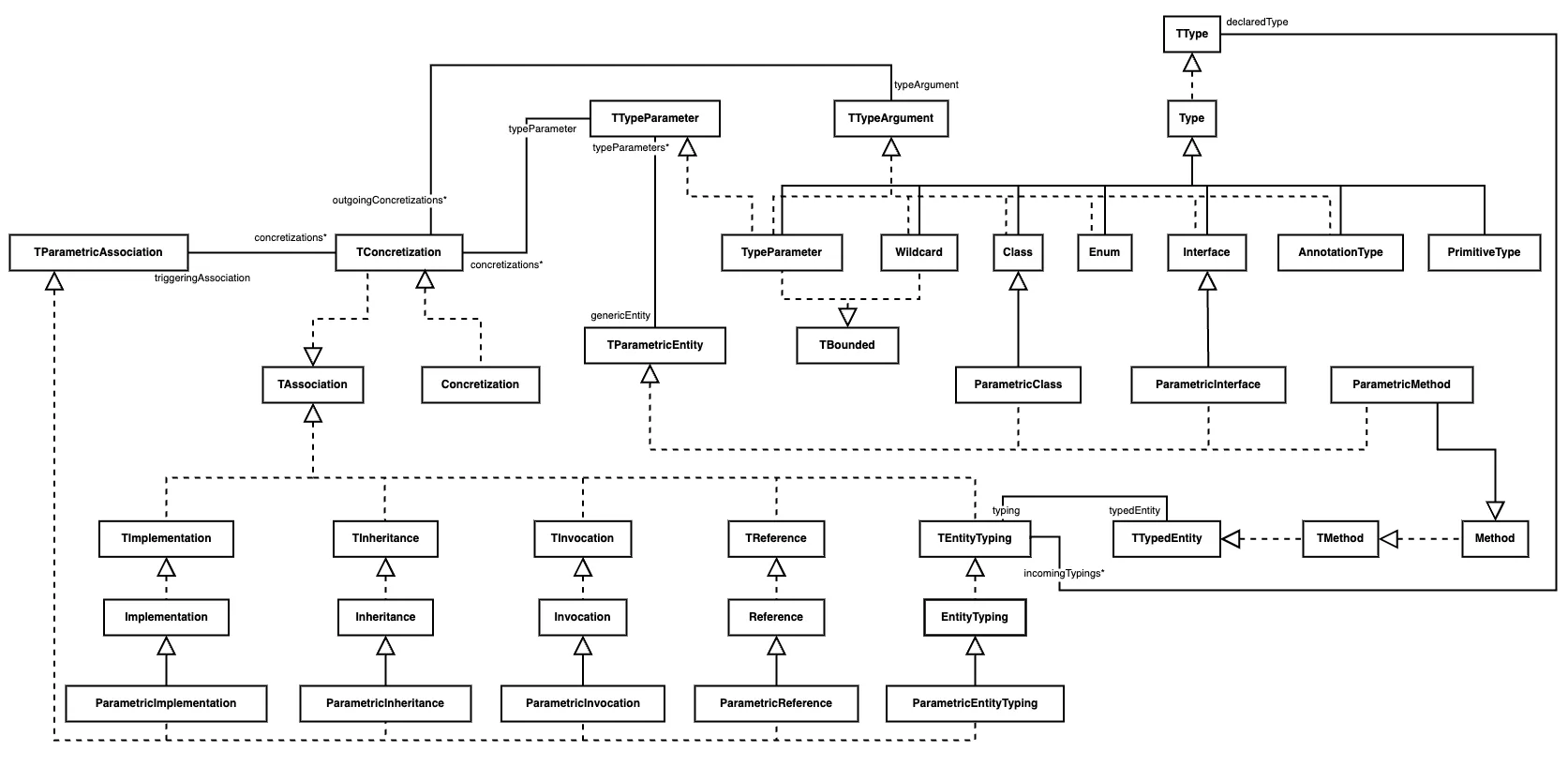
Section titled “Summary”This diagram sums up the new parametrics implementation in Famix traits and Java metamodel. Please note that this is not the full Java metamodel but only a relevant part.
What’s next?
Section titled “What’s next?”Should Concretization really be an association?
Section titled “Should Concretization really be an association?”The representation of parametric entities is a challenge that will most likely continue as Famix evolves. The next question will probably be this one: should Concretization really be an association?
An association is the reification of a dependency. Yet, there is no dependency between a type argument and the type parameter it replaces. Each can exist without the other. The dependency is in fact between the source of the parametric association and the type parameter.
With one of our previous examples:
public MySpecializedList extends ArrayList<String> {}MySpecializedList has a superclass (ArrayList<E>) and also depends on String, as a type argument. However, String does not depend on E neither E on String.
The next iteration of the representation of parametric entities will probably cover this issue. Stay tuned!