How do we represent the relation between a generic entity, its type parameters and the entities that concretize it? The Famix metamodel has evolved over the years to improve the way we represent these relations. The last increment is described in a previous blogpost.
We present here a new implementation that eases the management of parametric entities in Moose.
The major change between this previous version and the new implementation presented in this post is this:
We do not represent the parameterized entities anymore.
What’s wrong with the previous parametrics implementation?
The major issue with the previous implementation was the difference between parametric and non-parametric entities in practice, particularly when trying to trace the inheritance tree.
Here is a concrete example: getting the superclass of the superclass of a class.
For a non-parametric class, the sequence is straightforward: ask the inheritance for the superclass, repeat.
For a parametric class (see the little code snippet below), there was an additional step, navigating through the concretization:
importjava.util.ArrayList; "public class ArrayList<E> { /* ... */ }"
This has caused many headaches to developers who wanted to browse a hierarchy: how do we keep track of the full hierarchy when it includes parametric classes? How to manage both situations without knowing if the classes will be parametric or not?
The same problem occurred to browse the implementations of parametric interfaces and the invocations of generic methods.
Each time there was a concretization, a parametric entity was created. This created duplicates of virtually the same entity: one for the generic entity and one for each parameterized entity.
Let’s see an example:
publicMyClass implements List<Float> {
publicList<Integer>getANumber() {
List<Number> listA;
List<Integer> listB;
}
}
For the interface List<E>, we had 6 parametric interfaces:
One was the generic one: #isGeneric >>> true
3 were the parameterized interfaces implemented by ArrayList<E>, its superclass AbstractList<E> and MyClass. They were different because the concrete types were different: E from ArrayList<E>, E from AbstractList<E>and Float.
2 were declared types: List<Number> and List<Integer>.
When deciding of a new implementation, our main goal was to create a situation in which the dependencies would work in the same way for all entities, parametric or not.
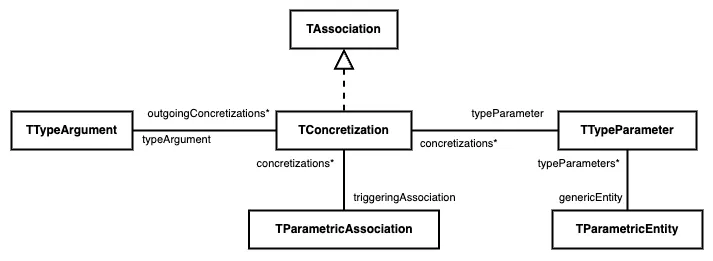
That’s where we introduce parametric associations. These associations only differ from standard associations by one property: they trigger a concretization.
Here is the new Famix metamodel traits that represent concretizations:
There is a direct relation between a parametric entity and its type parameters.
A concretization is the association between a type parameter and the type argument that replaces it.
A parametric association triggers one or several concretizations, according to the number of type parameters the parametric entity has. Example: a parametric association that targets Map<K,V> will trigger 2 concretizations.
The parametric entity is the target of the parametric association. It is always generic. As announced, we do not represent parameterized entities anymore.
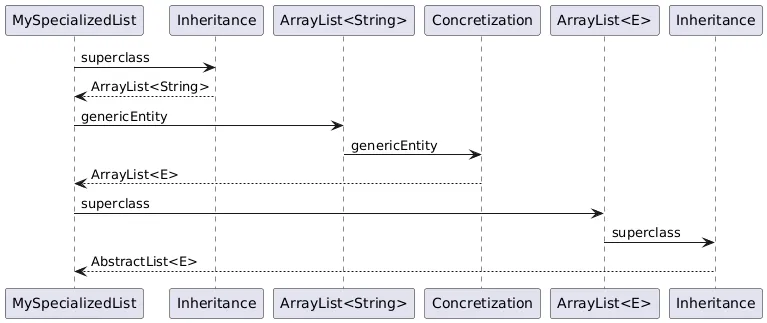
Coming back to the entities’ duplication example above, we now represent only 1 parametric interface for List<E>and it is the target of the 5 parametric associations.
This metamodel evolution is the occasion of another major change: the replacement of the direct relation between a typed entity and its type. This new association is called Entity typing.
The choice to replace the existing relation by a reified association is made to represent the dependency in coherence with the rest of the metamodel.
With this new association, we can now add parametric entity typings.
In a case like this:
publicArrayList<String> myAttribute;
we have an “entity typing” association between myAttribute and ArrayList. This association is parametric: it triggers the concretization of E in ArrayList<E> by String.
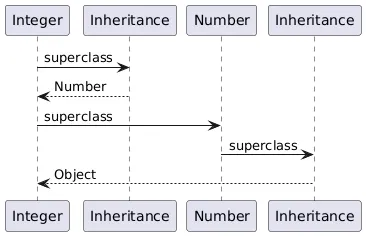
In the previous implementation, the bounds of type parameters were implemented as inheritances: in the example above, Number would be the superclass of T.
Since this change, bounds were introduced for wildcards.
We have now the occasion to also apply them to type parameters.
In the new implementation, Number is the upper bound of T.
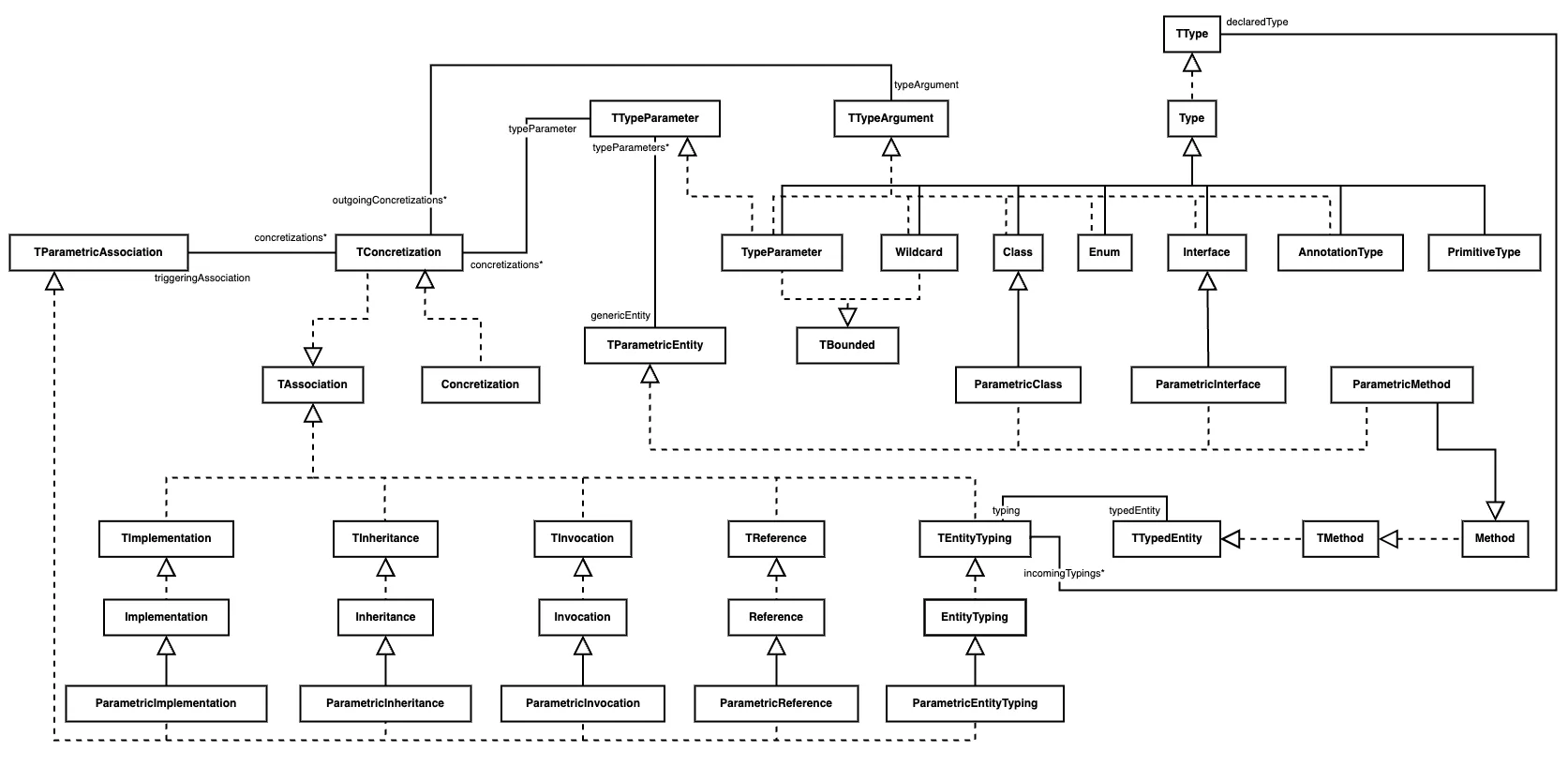
This diagram sums up the new parametrics implementation in Famix traits and Java metamodel.
Please note that this is not the full Java metamodel but only a relevant part.
The representation of parametric entities is a challenge that will most likely continue as Famix evolves. The next question will probably be this one: should Concretization really be an association?
An association is the reification of a dependency. Yet, there is no dependency between a type argument and the type parameter it replaces. Each can exist without the other. The dependency is in fact between the source of the parametric association and the type parameter.
MySpecializedList has a superclass (ArrayList<E>) and also depends on String, as a type argument. However, String does not depend on E neither E on String.
The next iteration of the representation of parametric entities will probably cover this issue. Stay tuned!
In this blog-post, we see some tricks to create a visitor for an alien AST.
This visitor can allow, for example, to generate a Famix model from an external AST.
In a previous blog-post, we saw how to create a parser from a tree-sitter grammar.
This parser gives us an AST (Abstract Syntax Tree) which is a tree of nodes representing any given program that the parser can understand.
But the structure is decided by the external tool and might not be what we want.
For example it will not be a Famix model.
Let see some tricks to help convert this alien grammar into something that better fits our needs.
Let’s first look at what a “Visitor” is.
If you already know, you can skip this part.
When dealing with ASTs or Famix models, visitors are very convenient tools to walk through the entire tree/model and perform some actions.
The Visitor is a design pattern that allows to perform some actions on a set of interconnected objects, presumably all from a family of classes.
Typically, the classes all belong to the same inheritance hierarchy.
In our case, the objects will all be nodes in an AST.
For Famix, the objects would be entities from a Famix meta-model.
In the Visitor pattern, all the classes have an #accept: method.
Each #accept: in each class will call a visiting method of the visitor that is specific to it.
For example the classes NodeA and NodeB will respectively define:
NodeA >> accept: aVisitor
aVisitor visitNodeA: self.
NodeB >> accept: aVisitor
aVisitor visitNodeB: self.
Each visiting method in the visitor will with the element it receives, knowing what is its class: in #visitNodeA: the visitor knows how to deal with a NodeA instance and similarly for #visitNodeB:.
The visitor pattern is a kind of ping-pong between the visiting and #accept: methods:
Typically, all the node are interconnected in a tree or a graph.
To walk through the entire structure, it is expected that each visiting method take care of visiting the sub-objects of the current object.
For example we could say that NodeA has a property child containing another node:
NodeVisitor >> visitNodeA: aNodeA
"do some stuff"
aNodeA child accept: self
It is easy to see that if child contains a NodeB, this will trigger the visiting method visitNodeB: on it.
If it’s a instance of some other class, similarly it will trigger the appropriate visiting method.
To visit the entire structure one simply calls accept: on the root of the tree/graph passing it the visitor.
Visitors are very useful with ASTs or graphs because once all the accept: methods are implemented, we can define very different visitors that will "do some stuff" (see above) on all the object in the tree/graph.
Several of the “Famix-tools” blog-posts are based on visitors.
In a preceding blog-post we saw how to create an AST from a Perl program using the Tree-Sitter Perl grammar.
We will use this as an example to see how to create a visitor on this external AST.
Here “external” means it was created by an external tool and we don’t have control on the structure of the AST.
If we want to create a Famix-Perl model from a Tree-Sitter AST, we will need to convert the nodes in the Tree-Sitter AST into Famix entities.
(Note: In Perl, “package” is used to create classes. Therefore in our example, “new”, “setFirstName”, and “getFirstName” are some kind of Perl methods.)
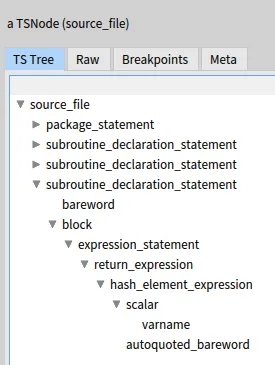
Following the instructions in the previous post, you should be able to get a Tree-Sitter AST like this one:
To have a visitor for this AST, we first need to have an accept: method in all the classes of the AST’s nodes.
Fortunately this is all taken care of by the Pharo Tree-Sitter project.
In TSNode one finds:
accept: aTSVisitor
^ aTSVisitor visitNode: self
And a class TSVisitor defines:
visitNode: aTSNode
aTSNode collectNamedChild do: [ :child|
child accept: self ]
Which is a method ensuring that all children of a TSNode will be visited.
Thanks guys!
But less fortunately, there are very few different nodes in a Tree-Sitter AST.
Actually, all the nodes are instances of TSNode.
So the “subroutine_declaration_statement”, “block”, “expression_statement”, “return_expression”,… of our example are all of the same class, which is not very useful for a visitor.
This happens quite often.
For example a parser dumping an AST in XML format will contain mostly XMLElements.
If it is in JSON, they are all “objects” without any native class specification in the format. 😒
Fortunately, people building ASTs usually put inside a property with an indication of the type of each node.
For Tree-Sitter, this is the “type” property.
Every TSnode has a type which is what is displayed in the screenshot above.
How can we use this to help visiting the AST in a meaningfull way (from a visitor point a view)?
We have no control on the accept: method in TSNode, it will always call visitNode:.
But we can add an extra indirection to call different visiting methods according to the type of the node.
So, our visitor will inherit from TSVisitor but it will override the visitNode: method.
The new method will take the type of the node, build a visiting method name from it, and call the method on the node.
Let’s decide that all our visiting methods will be called “visitPerl<some-type>”.
For example for a “block”, the method will be visitPerlBlock:, for a “return_expression” it will be `visitPerlReturn_expression:”.
This is very easily done in Pharo with this method:
visitNode: aTSNode
| selector |
selector :='visitPerl', aTSNode type capitalized ,':'.
^self perform: selector asSymbol with: aTSNode
This method builds the new method name in a temporary variable selector and then calls it using perform:with:.
Note that the type name is capitalized to match the Pharo convention for method names.
We could have removed all the underscores (_) but it would have required a little bit of extra work.
This is not difficult with string manipulation methods.
You could try it… (or you can continue reading and find the solution further down.)
With this simple extra indirection in #visitNode:, we can now define separate visiting method for each type of TSNode.
For example to convert the AST to a Famix model, visitPerlPackage: would create a FamixPerlClass, and visitPerlSubroutine_declaration_statement: will create a FamixPerlMethod.
(Of course it is a bit more complex than that, but you got the idea, right?)
Our visitor is progressing but not done yet.
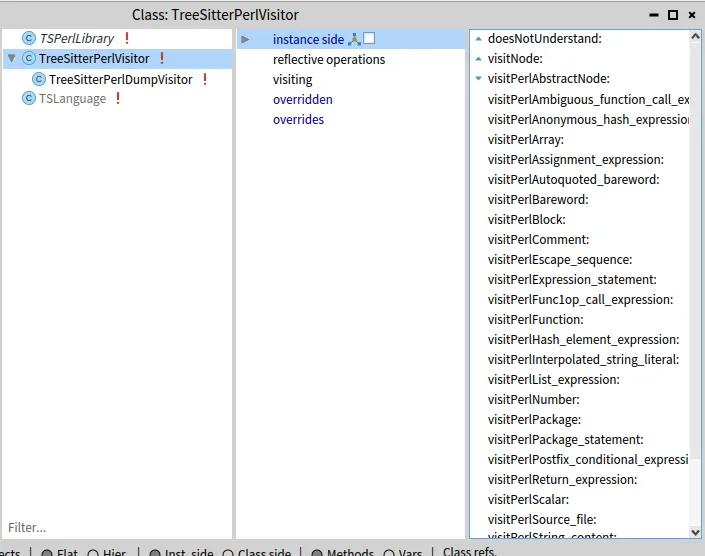
If we call astRootNode accept: TreeSitterPerlVisitor new with the root node of the Tree-Sitter AST, it will immediately halt on a DoesNotUnderstand error because the method visitPerlSource_file: does not exist in the visitor.
We can create it that way:
visitPerlSource_file: aTSNode
^self visitPerlAbstractNode: aTSNode.
visitPerlAbstractNode: aTSNode
^super visitNode: aTSNode
Here we introduce a visitPerlAbstractNode: that is meant to be called by all visiting methods.
From the point of view of the visitor, we are kind of creating a virtual inheritance hierarchy where each specific TSNode will “inherit” from that “PerlAbstractNode”.
This will be useful in the future when we create sub-classes of our visitor.
By calling super visitNode:, in visitPerlAbstractNode: we ensure that the children of the “source_file” will be visited.
And… we instantly get a new halt with DoesNotUnderstand: visitPerlPackage_statement:.
Again we define it:
visitPerlPackage_statement: aTSNode
^self visitPerlAbstractNode: aTSNode
This is rapidly becoming repetitive and tedious. There are a lot of methods to define (25 for our example) and they are all the same.
Let’s improve that.
We will use the Pharo DoesNotUnderstand mechanism to automate everything.
When a message is sent that an object that does not understand it, then the message doesNotUnderstand: is sent to this object with the original message (not understood) as parameter.
The default behavior is to raise an exception, but we can change that.
We will change doesNotUnderstand: so that it creates the required message automatically for us.
This is easy all we need to do is create a string:
visitPerl<some-name>: aTSNode
^self visitPerlAbstractNode: aTSNode
We will then ask Pharo to compile this method in the Visitor class and to execute it.
et voila!
Building the string is simple because the selector is the one that was not understood originally by the visitor.
We can get it from the argument of doesNotUnderstand:.
So we define the method like that:
doesNotUnderstand: aMessage
| code |
code := aMessage selector ,' aTSNode
^super visitNode: aTSNode'.
selfclass compile: code classified: #visiting.
self perform: aMessage selector with: aMessage arguments first
First we generate the source code of the method in the code variable.
Then we compile it in the visitor’s class.
Last we call the new method that was just created.
Here to call it, we use perform:with: again, knowing that our method has only one argument (so only one “with:” in the call).
For more security, it can be useful to add the following guard statement at the beginning of our doesNotUnderstand: method:
(aMessage selector beginsWith: 'visitPerl')
ifFalse: [ super doesNotUnderstand: aMessage ].
This ensures that we only create methods that begins with “visitPerl”, if for any reason, some other message is not understood, it will raise an exception as usual.
Now visiting the AST from our example creates all the visiting methods automatically:
Of course this visitor does not do anything but walking through the entire AST.
Let’s say it is already a good start and we can create specific visitors from it.
For example we see in the screen shot above that there is a TreeSitterPerlDumpVisitor.
It just dumps on the Transcript the list of node visited.
For this, it only needs to define:
visitPerlAbstractNode: aTSNode
('visiting a ', aTSNode type) traceCr.
super visitPerlAbstractNode: aTSNode.
Et voila! (number 2)
Note: Redefining doesNotUnderstand: is a nice trick to quickly create all the visiting methods, but it is recommended that you remove it once the visitor is stable, to make sure you catch all unexpected errors in the future.
This is all well and good, but the visiting methods have one drawback:
They visit the children of a node in an unspecified order.
For example, an “assignment_expression” has two children, the variable assigned and the expression assigned to it.
We must rely on Tree-Sitter to visit them in the right order so that the first child is always the variable assigned and the second child is always the right-hand-side expression.
It would be better to have a name for these children so as to make sure that we know what we are visiting at any time.
In this case, Tree-Sitter helps us with the collectFieldNameOfNamedChild method of TSNode.
This method returns an OrderedDictionary where the children are associated to a (usually) meaningful key.
In the case of “assignment_expression” the dictionary has two keys: “left” and “right” each associated to the correct child.
It would be better to call them instead of blindly visit all the children.
So we will change our visitor for this.
The visitNode: method will now call the visiting method with the dictionnary of keys/children as second parameter, the dictionnary of fields.
This departs a bit from the traditional visitor pattern where the visiting methods usually have only one argument, the node being visited.
But the extra information will help make the visiting methods simpler:
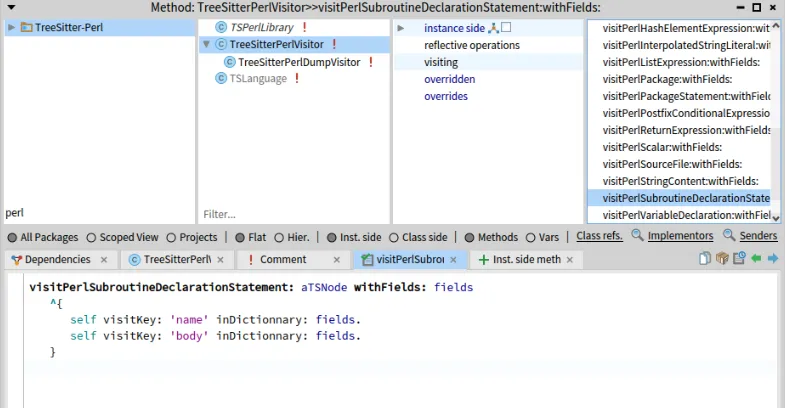
visitNode: aTSNode
| selector |
selector := String streamContents: [ :st|
st <<'visitPerl'.
($_ split: aTSNode type) do: [ :word| st << word capitalized ].
st <<':withFields:'
].
^self
perform: selector asSymbol
with: aTSNode
with: aTSNode collectFieldNameOfNamedChild
It looks significantly more complex, but we also removed the underscores (_) in the visiting method selector (first part of the #visitNode: method).
So for “assignment_expression”, the visiting method will now be: visitPerleAssignmentExpression:withFields:.
From this, we could have the following template for our visiting methods:
Again, it may look a bit complex, but this is only building a string with the needed source code. Go back to the listing of #visitPerlAssignmentExpression: above to see that:
we first build the selector of the new visiting method with its parameter;
then we put a return and start a dynamic array;
after that we create a call to #visitKey:inDictionnary for each field;
and finally, we close the dynamic array.
Et voila! (number 3).
This is it.
If we call again this visitor on an AST from Tree-Sitter, it will generate all the new visiting methods with explicit field visiting.
For example:
The implementation of all this can be found in the https://github.com/moosetechnology/Famix-Perl repository on github.
All that’s left to do is create a sub-class of this visitor and override the visiting methods to do something useful with each node type.
In this post, we will be looking at how to use a Tree-Sitter grammar to help build a parser for a language.
We will use the Perl language example for this.
Note: Creating a parser for a language is a large endehavour that can easily take 3 to 6 months of work.
Tree-Sitter, or any other grammar tool, will help in that, but it remains a long task.
do make (note: it gave me some error, but the library file was generated all the same)
(on Linux) it creates a libtree-sitter-perl.so dynamic library file.
This must be moved in some standard library path (I chose /usr/lib/x86_64-linux-gnu/ because this is where the libtree-sitter.so file was).
Pharo uses FFI to link to the grammar library, that’s why it’s a good idea to put it in a standard directory.
You can also put this library file in the same directory as your Pharo image, or in the directory where the Pharo launcher puts the virtual machines.
The subclasses of FFILibraryFinder can tell you what are the standard directories on your installation.
For example on Linux, FFIUnix64LibraryFinder new paths returns a list of paths that includes '/usr/lib/x86_64-linux-gnu/' where we did put our grammar.so file.
We use the Pharo-Tree-Sitter project (https://github.com/Evref-BL/Pharo-Tree-Sitter) of Berger-Levrault, created by Benoit Verhaeghe, a regular contributor to Moose and this blog.
You can import this project in a Moose image following the README instructions.
Notice that we gave the name of the dynamic library file created above (libtree-sitter-perl.so).
If this file is in a standard library directory, FFI will find it.
We can now experiment “our” parser on a small example:
parser := TSParser new.
tsLanguage := TSLanguage perl.
parser language: tsLanguage.
string :='# this is a comment
my $var = 5;
'.
tree := parser parseString: string.
tree rootNode
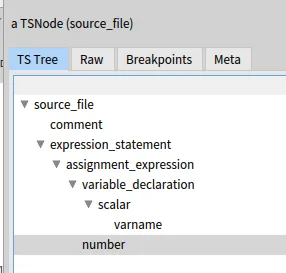
This gives you the following window:
That looks like a very good start!
But we are still a long way from home.
Let’s look at a node of the tree for fun.
node := tree rootNode firstNamedChild will give you the first node in the AST (the comment).
If we inspect it, we see that it is a TSNode
we can get its type: node type returns the string 'comment'
node nextSibling returns the next TSNode, the “expression-statement”
node startPoint and node endPoint tell you where in the source code this node is located.
It returns instances of TSPoint:
node startPoint row = 0 (0 indexed)
node startPoint column = 0
node endPoint row = 0
node endPoint column = 19
That is to say the node is on the first row, extending from column 0 to 19.
With this, one could get the text associated to the node from the original source code.
That’s it for today.
In a following post we will look at doing something with this AST using the Visitor design pattern.
When it comes to understand a software system, we are often focusing on the software artifact itself.
What are the classes? How they are connected with each other?
In addition to this analysis of the system, it can be interesting to explore how the system evolves through time.
To do so, we can exploit its git history.
In Moose, we developed the project GitProjectHealth that enables the analysis of git history for projects hosted by GitHub, GitLab, or BitBucket.
The project also comes with a set of metrics one could use directly.
For this first blog post, we will experiment GitProjectHealth on the Famix project.
Since this project is a GitHub project, we first create a GitHub token that will give GitProjectHealth the necessary authorization.
Then, we import the moosetechnology group (that hosts the Famix project).
group := githubImporter importGroup: 'moosetechnology'.
This first step allows us to get first information on projects.
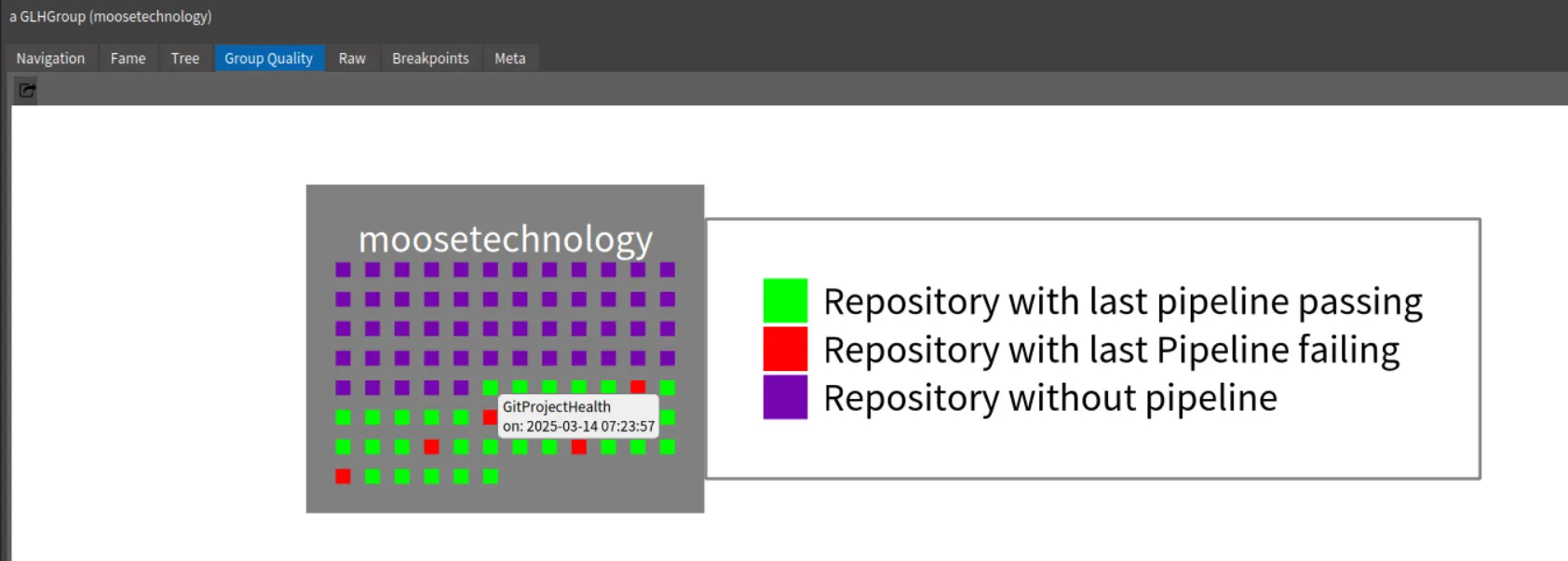
For instance, by inspecting the group, we can select the “Group quality” view and see the group projects and the last status of their pipelines.
Then, by navigating to the Famix project and its repository, you can view the Commits History.
.
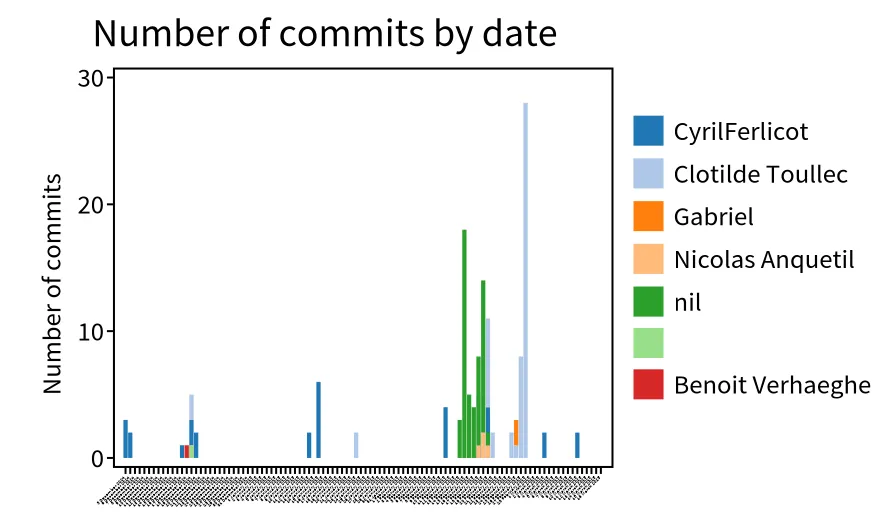
It is also possible to explore the recent commit distribution by date and author
.
In this visualization, we discover that the most recent contributors are “Clotilde Toullec” and “CyrilFerlicot”.
The “nil” refers to a commit authors that did not fill GitHub with their email. It is anquetil (probably the same person as “Nicolas Anquetil”).
The square without name is probably someone that did not fill correctly the local git config for username.
A popular metric when looking at git history is the code churn.
Code churn refer to edit of code introduced in the past.
It corresponds to the percentage of code introduced in a commit and then modified in other comments during a time period (e.g in the next week).
However many code churn definitions exit.
The first step is thus to discover what commits modified my code.
To do so, we implemented in GitProjectHealth information about diff in commit.
To extract this information, we first ask GitProjectHealth to extract more information for the commits of the famix project.
famix := group projects detect: [ :project| project name ='Famix' ].
"I want to go deeper in analysis for famix repository, so I complete commit import of this project"
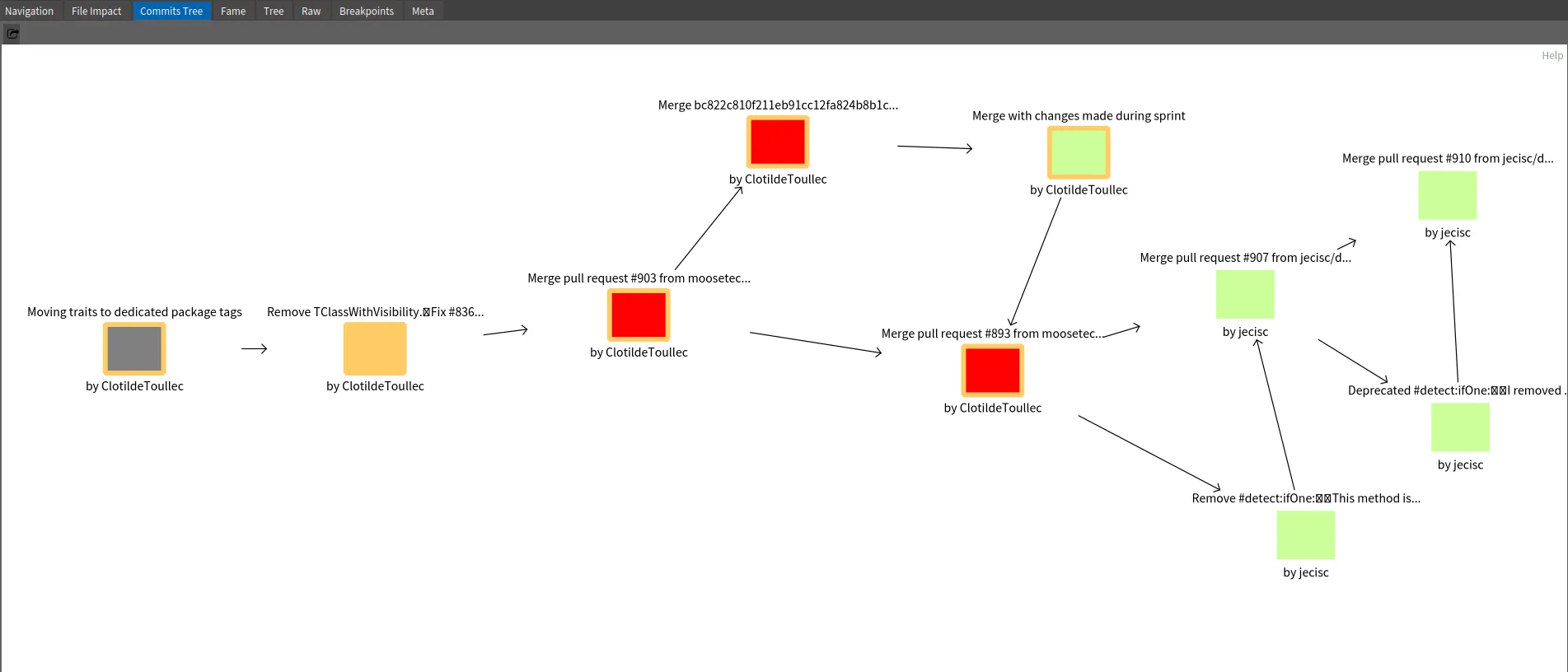
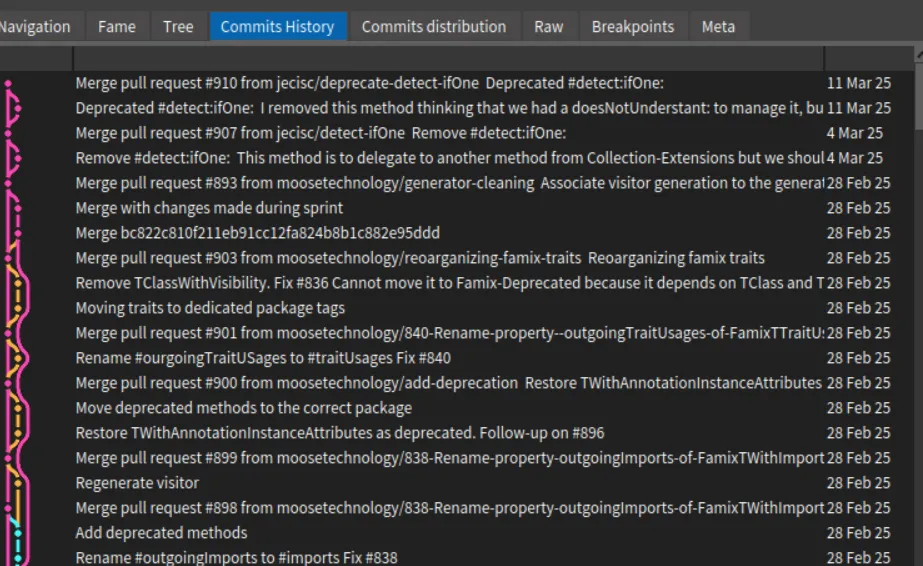
Then, when inspecting a commit, it is possible to switch to the “Commits tree” view.
Here how to read to above example
The orange square “Remove TClassWithVisibility…” is the inspected commit.
The gray square is the parent commit of the selected ones.
The red squares are subsequent commits that modify at least one file in common with the inspected commit
The green squares are commits that modifies other part of the code
Based on this example, we see that Clotilde Toullec modifies code introduced in selected commits in three next commits.
Two are Merged Pull Request.
This can represent linked work or at least actions on the same module of the application.
It is possible to go even deeper in the analysis by connecting GitProjectHealth with other analysis.
This is possible by connecting metamodels.
For instance, it is possible to link GitProjectHealth with Jira system, of Famix models.
You can look at the first general documentation, or stay tune for the next blog post about GitProjectHealth!
Control Flow Graphs (CFG) are a common tool for static analyzis of a computation unit (eg. a method) and find some errors (unreachable code, infinite loops)
It is based on the concept of Basic Block: a sequence of consecutive statements in which flow of control can only enter at the beginning and leave at the end. Only the last statement of a basic block can be a branch statement and only the first statement of a basic block can be a target of a branch.
There are two distinctive basic blocks:
Start Block: The entry block allows the control to enter into the control flow graph. There should be only one start block.
Final Block: Control flow leaves through the exit block. There may be several final blocks.
The package FAST-Fortran-Analyses in https://github.com/moosetechnology/FAST-Fortran contains classes to build a CFG of a Fortran program unit (a main program, a function, or a subroutine).
We must first create a FAST model of a Fortran program.
For this we need an external parser.
We currently use fortran-src-extras from https://github.com/camfort/fortran-src-extras.
This will produce a json AST of the program that we can turn into a FAST-Fortran AST.
If you have fortran-src-extras installed on your computer, all this is automated in FAST-Fortran
<fortran-file.f> asFileReference
readStreamDo: [ :st|
FortranProjectImporter new getFASTFor: st contents ]
This script will create an array of ASTs from the <fortran-file.f> given fortran file.
If there are several program units in the file, there will be several FAST models in this array.
In the example below, there is only one program, so the list contains only the AST for this program.
We will use the following Fortran-77 code:
PROGRAM EUCLID
* Find greatest common divisor using the Euclidean algorithm
This visitor goes throught the FAST model and creates a list of basic blocks that can be inspected with the #basicBlocks method.
There is a small hierarchy of basic block classes:
FASTFortranAbstractBasicBlock, the root of the hierarchy.
It contains #statements (which are FAST statement nodes).
It has methods to test its nature: isStart, isFinal, isConditional.
It defines an abstract method #nextBlocks that returns a list of basic blocks that this one can directly reach.
Typically there are 1 or 2 next blocks, but Fortran can have more due to “arithmetic IF”, “computed GOTO” and “assigned GOTO” statements.
FASTFortranBasicBlock, a common basic block with no branch statement.
If it is final, its #nextBlocks is empty, otherwise it’s a list of 1 block.
FASTFortranConditionalBasicBlock, a conditional basic block.
It may reach several #nextBlocks, each one associated with a value, for example true and false.
The method #nextBlockForValue: returns the next block associated to a given value.
In our version of CFG, a conditional block may only have one statement (a conditional statement).
You may have noticed that our blocks are a bit different from the definition given at the beginning of the blog-post:
our “common” blocs cannot have several next, they never end with a conditional statement;
our conditional blocks can have only one statement.
For the program above, the CFG has 10 blocks.
the first block is a common block and contains 2 statements, the PRINT and the READ;
its next bloc is a conditional block for the IF.
It has 2 next blocs:
true leads to a common block with 2 statements, the PRINT and the STOP. This is a final block (STOP ends the program);
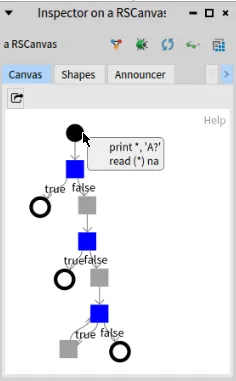
As a first analysis tool, we can visualize the CFG.
Inspecting the result of the next script will open a Roassal visualization on the CFG contained in the FASTFortranCFGVisitor.
FASTFortranCFGVisualization on: <aFASTFortranCFGVisitor>
For the program above, this gives the visualization below.
the dark dot is the starting block (note that it is a block and contains statements);
the hollow dots are final blocks;
it’s not the case here, but a block may also be start and final (if there are no conditional blocks in the program) and this would be represented by a “target”, a circle with a dot inside;
a grey square is a comon block;
a blue square is a conditional block;
hovering the mouse on a block will bring a pop up with the list of its statements (this relies on the FASTFortranExporterVisitor)
One can see that:
the start block has 2 associated statements (PRINT and READ);
there are several final blocks, due to the STOP statements;
there is a loop at the bottom left of the graph where the last blue conditional block is “IF (IB.NE.0)” and the last statement of the grey block (true value of the IF), is a GOTO.
There are little analyses for now on the CFG, but FASTFortranCFGChecker will compute a list of unreachableBlocks that would represent dead code.
Control flow graphs may also be used to do more advanced analyses and possibly refactor code.
For example, we mentioned the loop at the end of our program implemented with a IF statement and a GOTO.
This could be refactored into a real WHILE loop that would be easier to read.
This is left as an exercise for the interested people 😉
Building a control flow graph is language dependant to identify the conditional statements, where they lead, and the final statements.
But much could be done in FAST core based on FASTTReturnStatement and a (not yet existing at the time of writing) FASTTConditionalStatement.
Inspiration could be taken from FASTFortranCFGVisitor and the process is not overly complicated.
It would probably be even easier for modern languages that do not have the various GOTO statements of Fortran.
Once the CFG is computed, the other tools (eg. the visualization) should be completely independant of the language.


 .
. .
.